Content Generation for GEO - Prompting, Quality Gates, and Scaling (Part 2 of 2)
GEO Content Marketing AI Strategy
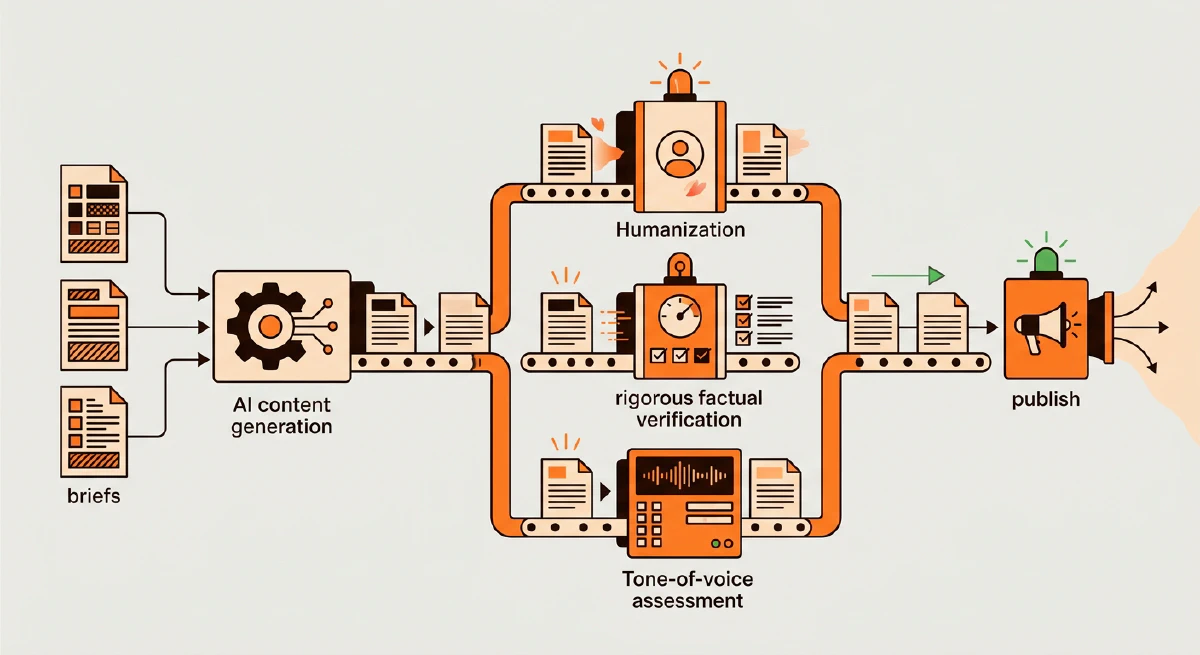
Brand-voice AI output requires more than a tone slider, and scaling past 25 pieces a month is where most operations break. Zeover trains on the brand’s existing content corpus, generates content with humanization and citation insertion built into the workflow, and ships the pipeline that makes high-volume production sustainable. Train on your brand voice.
Part 1 covered briefs: the seven-component structure that produces citable AI-generated drafts on the first pass. Part 2 covers everything downstream of the brief: prompting patterns that produce on-brand output, the post-draft quality layer that catches AI patterns and hallucinated facts, and the operational patterns that make 50+ pieces a month sustainable without quality collapse.
TL;DR
- Brand-voice prompting requires two inputs: training data (30-50 well-edited pieces) and a governance document with voice, tone scales, and style rules.
- Two post-draft passes catch the problems AI drafts ship with: humanization (stripping AI patterns) and fact-check (verifying claims, inserting citations). Together they save 30-60 minutes of editor time per piece.
- 50+ pieces a month is sustainable when the operation invests in role specialization (briefer, drafter, editor, validator as distinct roles), automated quality gates, and continuous benchmarking.
- Operations that institutionalize these patterns compound citation rate and content velocity. Operations that skip them produce generic content that gets indexed and ignored.
Prompting for Brand Voice at Scale
Generic prompts produce generic content. The 2023 generation of AI writing tools defaulted to model-base voice; the 2026 generation can be trained or prompted into brand voice if the team puts the work in.
The Dual Inputs
Training data. The existing brand corpus drives voice calibration. Quality matters more than quantity: 30-50 well-edited pieces from the last 6-12 months train brand voice better than 200 mixed-quality pieces. The pieces should be editor-approved, span varied formats (long-form, short-form, FAQ, case studies), and represent the voice the brand wants going forward, not the voice it had two years ago.
Governance document. The same source-of-truth document from prior series work. Positioning sentence, customer categories, brand voice notes, hard-banned vocabulary, forbidden patterns, approved transitions. The document goes into the prompt as context so the AI keeps the draft on voice and on brand.
Patterns That Anchor Voice
Few-shot examples in the voice block. Three short example pieces calibrate voice better than a written description of the voice. The AI mimics what it reads more reliably than what it’s told to do.
Explicit style rules. Hard-banned vocabulary, forbidden patterns, paragraph contract. The rules act as a checklist the AI applies during generation rather than a vague style guide it might ignore.
Citation hooks. Marking expected citations in the brief tells the AI exactly where to insert links and reduces hallucination of made-up sources.
The Post-Draft Quality Layer
After the draft lands and before the editor sees it, two passes do most of the mechanical work.
The Humanization Pass
What it catches:
- Uniform sentence length. AI drafts default to runs of 18-25 word sentences. The humanizer breaks the pattern, mixing 8-word sentences with 22-word sentences with the occasional 35-word sentence. Variation is harder to fake than rhythm.
- Em dash and en dash overuse. AI tools default to em dashes for parenthetical asides. Replaced with regular hyphens or sentence rewrites.
- Hedge stacks. “It could potentially be argued that this might have some effect” gets rewritten to “this affects X” or removed.
- Formulaic openers. “Here is what,” “Let me be clear,” and similar hedging phrases. Detected and replaced.
- Banned vocabulary. Each detected hit triggers a rewrite of the surrounding sentence.
- Tripling. Triple groupings used as default rhythm get mixed with twos and fours to break the pattern.
- Conclusion-by-promise. “The future of X remains to be seen.” Replaced with concrete claims, specific questions, or recommended actions.
The pass takes 1-3 minutes per piece for a 1,500-2,500 word draft. Operations running it save 30-45 minutes of editor time per piece.
The Fact-Check Pass
What it does:
- Identify factual claims. Statistics, percentages, dollar amounts, dates, named-entity attributions. Each gets flagged as a claim requiring verification.
- Search primary sources. Government data, academic papers, established news outlets, vendor documentation. Press releases only when they’re the primary source.
- Insert citations inline. A markdown hyperlink at the point of the claim, not a footnote at the end of the piece.
- Flag unverifiable claims. When no primary source exists within a confidence threshold, the claim gets tagged for the writer or editor to resolve.
- Update stale citations. When a citation rots (404, paywall, deprecated source), the pass replaces with a current equivalent or flags for review.
The pass takes 2-5 minutes per piece. Manual fact-checking on a long piece can consume 30-90 minutes depending on claim density.
Source Quality Hierarchy
The fact-check pass should prefer primary sources in this order: (1) peer-reviewed research and university publications, (2) government and regulatory bodies, (3) standards bodies and academic institutions, (4) established public news outlets, (5) vendor documentation for their own products, (6) press releases when they are the primary source. Wikipedia and aggregator blogs aren’t primary sources.
What Quality Gates Don’t Replace
Three patterns the quality layer can’t catch: editorial misjudgment (says the right things in the right voice but misses the strategic point), brand-positioning drift (follows the rules but subtly misrepresents the brand), and sensitive content (legal, medical, regulatory claims). The gates reduce mechanical work so the editor’s time goes to the work that requires judgment.
Scaling to 50+ Pieces a Month
The default 2026 outcome for operations attempting 50+ pieces a month is quality collapse: editors get overwhelmed, fact-checking gets skipped, voice drifts, citation rates decline. The exceptions invest in workflow, specialization, and quality gates that scale with volume.
The Volume Threshold Map
- 8-15 pieces a month: Manual workflow works. Editors review each piece deeply.
- 15-25 pieces a month: Briefs become required. Quality gates start to matter.
- 25-50 pieces a month: Role specialization becomes load-bearing. Editors specialize by content type. Quality gates run automatically.
- 50-100 pieces a month: Automation handles mechanical work. Editors review the strongest 60% deeply and spot-check the rest. Continuous benchmarking is essential.
- 100+ pieces a month: The operation is its own department with a dedicated operations role and multiple editor sub-teams.
The threshold beyond which quality collapses depends on workflow, not volume number. Operations with strong briefs, automated gates, and specialized editors can sustain 75 pieces a month. Operations with weak workflow collapse at 30.
Role Specialization
The five roles a 50-piece operation needs:
Content owner / briefer. Writes the seven-component briefs. Owns the editorial calendar. Reviews monthly benchmark data and converts findings into next-month priorities. Roughly 50% of one FTE.
AI drafter. Runs briefs through the AI tool. Verifies output against brief requirements. Routes drafts to the right editor. Often 25-50% of a FTE; sometimes a junior writer or operations specialist.
Editor (specialized by content type). Reviews drafts for brand voice, factual accuracy, paragraph contract, AI patterns. Two to three editors at scale, specialized by long-form / short-form / press / case study.
Validator. Owns the quality gates: humanization pass, fact-check pass, machine-readability check, brand voice score. Reviews the gates’ output and resolves edge cases. 25-50% of one FTE.
Benchmarking analyst. Runs cross-engine benchmarks. Closes the loop between citations earned and content briefed. 25% of one FTE, often shared across multiple content programs.
Total: 4-6 FTE for a 50-piece-a-month operation. Below this staffing, the math gets tight; above it, the operation can scale to 75-100 pieces with the same structure.
The Brief Volume Calculus
A 50-piece-a-month operation requires roughly 50 briefs a month. At 25-40 minutes per brief, that’s 21-33 hours of brief-writing time per month. The content owner role covers it. Teams that try to compress brief-writing to save time produce weaker briefs, which produce drafts that need heavier edits, which consumes editor time that tops the brief-writing savings. Brief-writing is the highest-ROI use of the content owner’s time.
Three Failure Modes at Volume
Editor saturation. One or two editors reviewing 50 pieces a month miss patterns, skip fact-checks, and burn out. Quality declines piece-by-piece in ways nobody traces back to the editor bottleneck. Fix: specialize editors and add the validator role.
Brief shortcut creep. Briefs get shorter to save content-owner time. Drafts get worse. Editor time per piece rises. Net velocity drops. Fix: protect the brief-writing time aggressively; treat it as the highest-ROI investment.
Benchmarking neglect. The operation ships volume without measuring whether the volume produces citations. Six months later, citation rate is flat or declining despite high output. Fix: monthly benchmarking is non-negotiable past 25 pieces a month.
Continuous Benchmarking
A 50-piece-a-month operation creates 600 pieces a year. Without benchmarking, the team can’t tell which pieces earned citations and which didn’t. The minimum shape: monthly cross-engine benchmark on the brand’s commercial prompt set, content-piece-to-citation mapping, per-piece pipeline tracking, and quarterly review of which content patterns earned citations consistently. The data feeds the next cycle’s briefs.
Closing
This two-part series argued that AI content generation is a practitioner discipline, not a tool decision. Part 1 covered briefs. Part 2 covered prompting, quality gates, and scaling.
The thread across both: AI content generation produces compounding returns when the operation invests in workflow, and compounding losses when it doesn’t. Briefs that include citation goals, prompts that anchor brand voice, quality gates that catch mechanical issues, and continuous benchmarking that closes the loop are the disciplines of a content operation that scales with quality intact.
The operations doing this in 2026 compound citation rate, content velocity, and pipeline. The operations skipping the workflow build up slop, lose visibility share, and end up cutting AI tool budgets while competitors invest harder. The gap is operational; the fix is too.


